被 Google 打臉了!Google Lighthouse 把llms.txt 列入檢測
- llms.txt 對 AI SEO 有沒有用?

上個禮拜才剛跟客戶拍胸脯說 llms.txt 對 SEO 沒有用。
結果這禮拜 Google Lighthouse 直接把它列入檢測項目,身為 SEO 顧問,這臉真的被打得又紅又腫。
我立刻在週未把Google 的文件完整讀過,發現 Google是先介紹了 Agentic browsing audits、WebMCP,然後才有Lighthouse 把llms.txt 列入檢測的段落。這是什麼一整連串的重點是什麼?三者之間又有什麼關係?
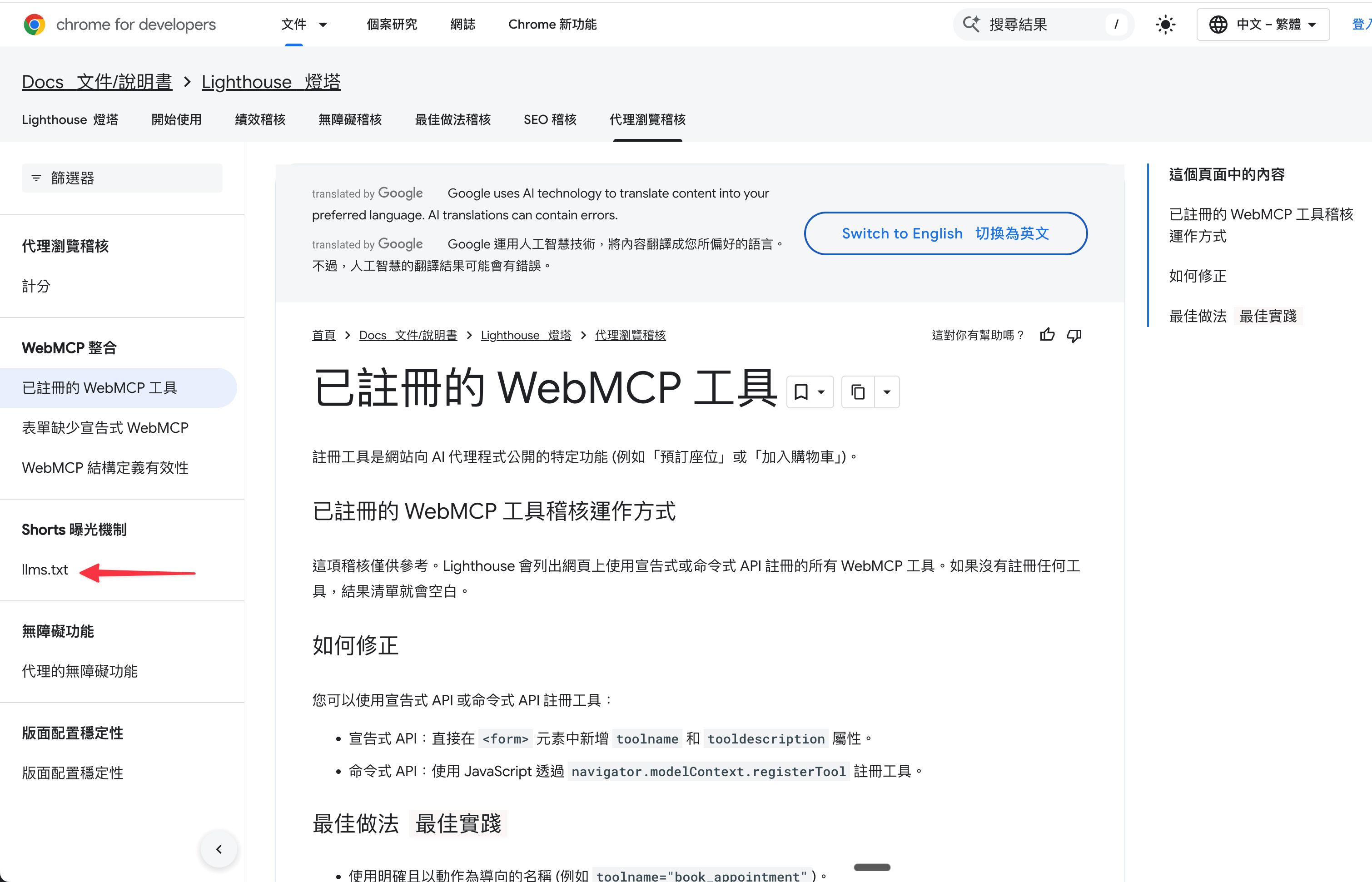
什麼是 Agent Browsing ?
Agent browsing(代理瀏覽)是由「AI 代理(AI Agent)」代替人類去瀏覽網頁、操作網站的行為。
例如,你對 AI 說:「幫我在東京訂一間 7 月 5 日、預算 5000 元台幣內、評價 4.5 顆星以上的雙人房。」
在Agent browsing 的機制下,AI 會自己執行以下步驟:
打開瀏覽器,主動連到 Agoda 或 Booking.com。
透過網頁的或視覺截圖,看懂搜尋框、日期選擇器在哪裡。
自動輸入「東京」、選擇「7 月 5 日」、勾選「雙人房」並按下搜尋。
滾動頁面、翻頁,閃過廣告,找出符合預算和4.5星以上評價的飯店。
最終挑選出 3 家飯店整理給你選。甚至可以得到你授權的情況下,直接幫你下單訂房。
更直白的話,Agent browsing不只幫你瀏覽,還把你要完成的事(Jobs-to-be-done),直接幫你給做了。
但是,傳統網頁是設計給「人類的眼睛」看的,充滿了複雜的排版、廣告和動態效果。如果 AI 代理直接硬闖,會很容易迷路或點錯按鈕。為了解決這個問題,就誕生了下面兩個基礎建設:WebMCP 與llms.txt。
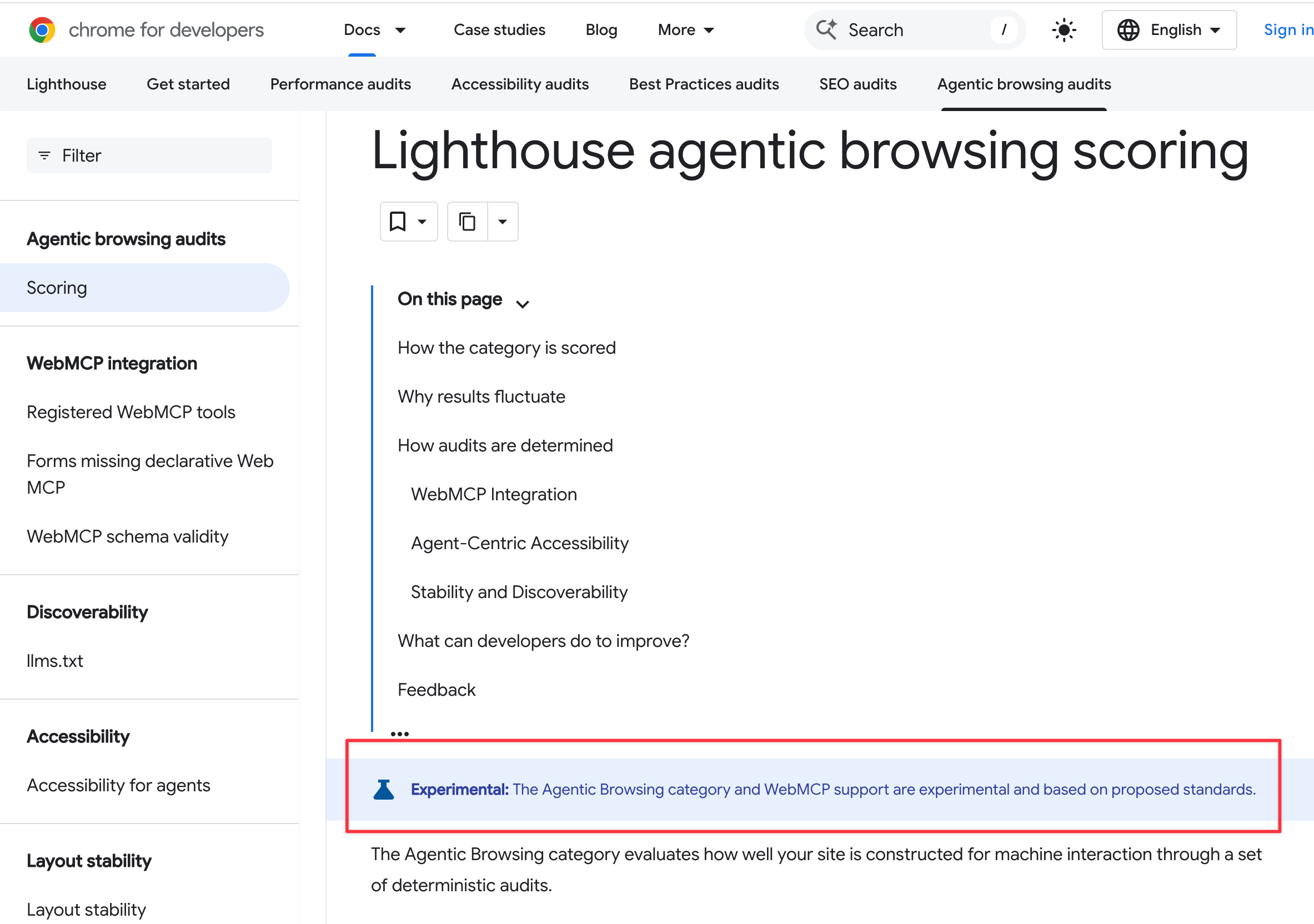
WebMCP是什麼?
WebMCP 是給AI用來「整合與執行」的工具,像是API。
因為Agent browsing 必須去「猜」網頁上的按鈕或輸入框在哪裡,很容易因為版面跑位而失敗。
有了 WebMCP,網站直接告訴 AI 有標準化的 API 工具(例如:明確定義出一個「搜尋日期與空房間」的工具與所需參數)。
Agent browsing 可以直接呼叫這個工具來完成表單送出或資料查詢,達到精準的操作。
注意:目前Agent browsing 和 WebMCP 都還是實驗性的,還有有標準化版本。
llms.txt 是什麼?
llms.txt 是一個放置在網站上的 Markdown 格式檔案,用來明確告訴 AI,這個網站「可以許做什麼」、「不能做什麼」,以及「重要的資源在哪裡」。
因為 AI 的上下文窗口有限,難以直接吞下整個網站上複雜的 HTML 網站(包含導覽列、廣告和 JavaScript)。
llms.txt 就是幫Agent browsing鋪好路、指明方向,讓 Agnet 能在最短的時間內知道「這個網站提供什麼服務」以及「關鍵功能(例如:下單頁面)在哪個網址」。
為什麼 Google Lighthouse 把llms.txt列入檢測?
我的解讀是這樣的:當一個網站有了WebMCP後,llms.txt是來協助 AI Agent 看懂一個網站的效率與準確度,是為了WebMCP做舖路。
當 AI 透過 llms.txt 決定要去某個特定頁面(例如:機票或飯店訂購頁)之後,它到了該頁面,才會正式調用 WebMCP 註冊的宣告式或命令式工具,進行精準的表單填寫與功能操作。
llms.txt 扮演高層次的導覽地圖,WebMCP 負責精準執行。
llms.txt就像是大型百貨公司門口的「精簡版樓層簡介手冊」, AI 讀了這本手冊(Markdown),一眼就知道 5 樓是餐廳、6 樓可以辦會員,讓 WebMCP去訂位或辦會員卡。
如果沒有 llms.txt 鋪路,AI 可能在網站迷路,或根本走不到部署了 WebMCP 的功能頁面。
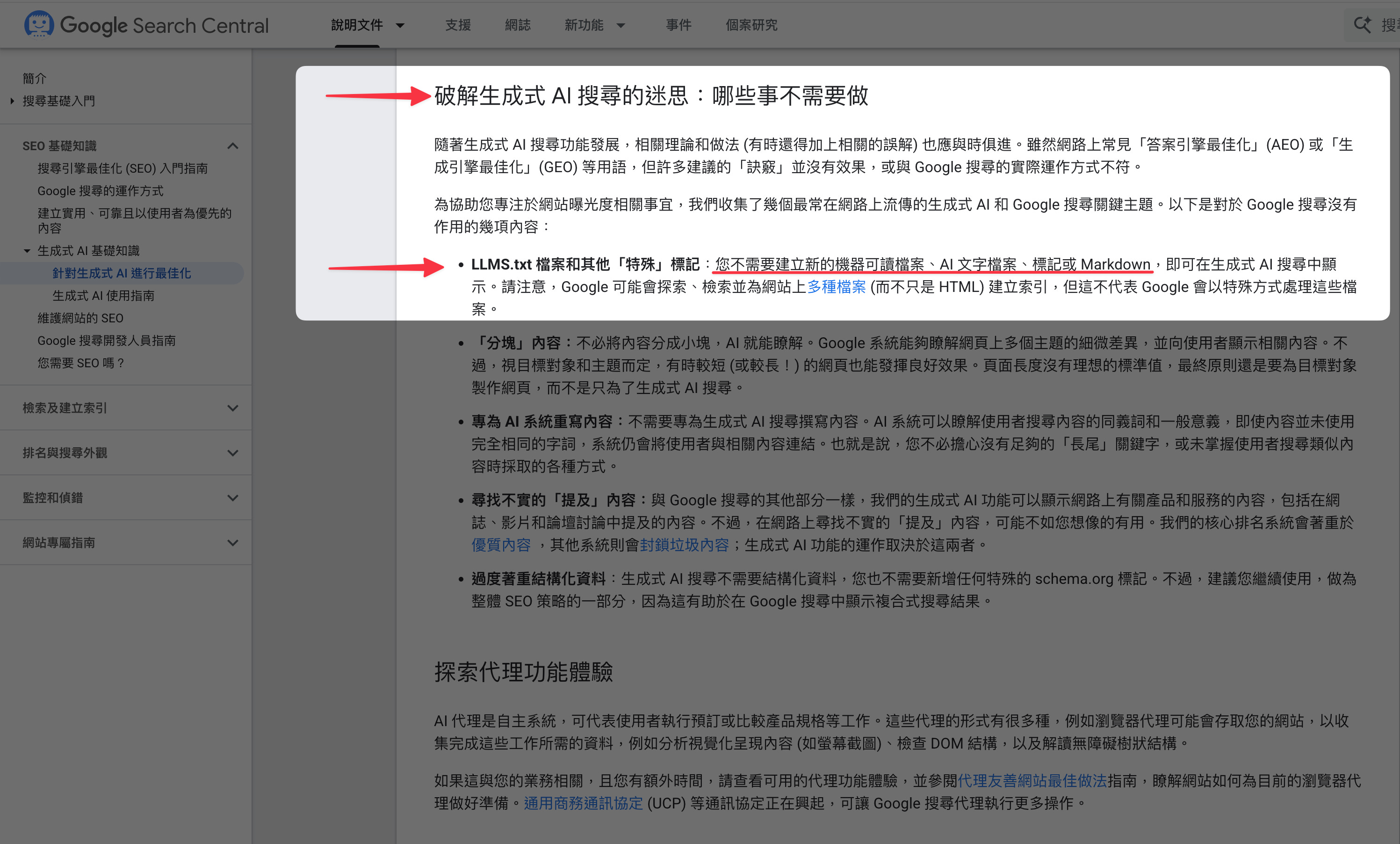
Google 的說法到底是什麼?
其實,Google 還是維持它的立場,不需要建立llms.txt或其它Markdown文件,就可以在生成式AI搜尋中出現。
llms.txt 能提升傳統搜尋結果SEO排名嗎?能提升AI引用與提及次數嗎?
我的看法:llms.txt 不會幫 SEO 排名,對AI引用或提及也沒啥沒影響。
因為llms.txt 不是為了提升 LLM 理解 HTML 的能力。llms.txt 是一個純 Markdown 檔案,它的本質是「主動繞過 HTML」,目的是讓 AI 直接略過那些繁雜的 HTML 標籤、CSS 樣式、廣告與 JavaScript 雜訊,直接讀取乾淨的結構化內容。所以,它的目的不是「教 AI 怎麼讀 HTML」,而是幫 AI 節省時間與運算成本。
簡單來說:
1. 對 SEO 排名:沒有差別,不裝也不會掉排名。
2. 對 AI 引用:目前 AI 還是能透過爬蟲抓到你的內容,有無 llm.txt 暫時不影響被引用的機會。至少我還沒看到有實驗數據証明。
3. 對「未來」 AI Agent:這才是差別所在。有了它,AI 代理人在幫使用者執行任務時會更準確、更高效。
但是,目前Agentic browsing 、WebMCP都還在實驗階段。如果你的網站不是SaaS平台、OTA平台等等,只是一般的品牌網站,那我會建議不要「AI 焦慮」,有個概念就好,不要現在就衝進去了。
與其花時間去維護那個給 AI 看的檔案,不如先把給人看的內容品質寫好。